Back to top: Project's history: the Texts domain
Back to top: Project's history: the Texts domain
1968-72: First experiments
The earliest intimation of what became the Cybernetica Mesopotamica project was in 1968. Emblematically, the sample text was the Code of Hammurapi: it was keypunched on a paper tape, and processed through an outsized mainframe computer, the only on campus for use by faculty and students. It had nothing more than the entire text in transliteration.
In the four years that followed, I experimented with other Old Babylonian texts, progressing from punched paper tape to punchcards and getting to learn about the interaction with the mainframe computer housed in the Engineering building on the UCLA campus. It was there that I ended up having, a small office on the ground floor which housed our own keypunch machine and was right next to the mainframe computer, where we would turn in our keypunched cards and get our fanfold outputs from a slot in the wall. (Because of my having this small office there, the first main office of the newly founded Institute of Archaeology was also housed in one of the upper floors of the Engineering building.)
In those years I also joined Peter Ladefoged’s phonetic lab in the Linguistics Department, and was indirectly introduced to the use of Assembly Language.
Back to top: Project's history: the Texts domain
Back to top: Project's history: the Texts domain
The corpus
These experiments triggered a proposal to the National Endowment for the Humanities, which resulted in a five year grant, one of the very first for (as it was called then) Computer Aided Research in the Humanities. The project was entitled OBLAP for Old Babylonian Linguistic Analysis Project, and it resulted in an exhaustive graphemic and morphemic analysis of the Old Babylonian letters as they were then being published by F.R. Kraus.
|
There were no means of circulating the results, which were included in fifteen very large fanfold printout volumes, about one thousand pages each: they are shown in the image to the right, where each volume contains the pertinent lines of the texts given in KWIC format (KeyWords In Context), sorted according to the standard Assyriological numeration of the signs.
|
|

|
The entire corpus was sorted according to the cuneiform signs given as triads.
From the beginning of the project, John L. Hayes was a central figure in both the philological and computer based aspects of the research.
All the main programming was supervised by John L. Settles.
Back to top: Project's history: the Texts domain
The main results
The results obtained were sophisticated and quite advanced for the time – the mid seventies(!). They fully showed the potential of the medium, and to a large extent they realized this potential as well, but the basic underlying problem was the difficulty in “publishing” them, i.e., in making them not only known, but also usable by other scholars.
There were two UCLA doctoral dissertations. Along with John L. Hayes, Yoshitaka Kobayashi and Paul W. Gaebelein were the most active members of the research group working on the project, and they completed their dissertations based on this research: Kobayashi in 1975 on Graphemic Analysis of Old Babylonian Letters from South Babylonia, and Gaebelein in 1976 on Graphemic Analysis of Old Babylonian Letters from Mari.
The results were summarized in G. Buccellati 1977. See a section on pp. 397-99 by John L. Settles about programming and pp. 399-401 on photo-composition by Sal Fallone. I give below a list of the three major outcomes.
Back to top: Project's history: the Texts domain
(1) Triadic graphemic sorts
The sort by cuneiform signs, according to their value, was produced on the entire corpus by selecting sequences of three signs, or "triads." It is the format found in the fifteen fanfold paper binders cited above. The one shown in the image to the right has the same format, but produced for offest printing with the addition of the cuneiform sign reproduced according to the standard Assyriological convention (see the next point.)
The concept of "triad" had significant linguistic implications. It showed that a graphemic sequence of three signs was the ideal mass for virtually eliminating the polyvalence inherent in the cuneiform system.
|
|

|
Back to top: Project's history: the Texts domain
In the absence of graphic interface software, a process of photocomposition was available that produced the signs by giving a long series of numbers referring to the position in a matrix, as shown in the image to the right.
The (very complex) process of producing the cuneiform signs was done manually by Yoshitaka Kobayashi.
|
|
|
Back to top: Project's history: the Texts domain
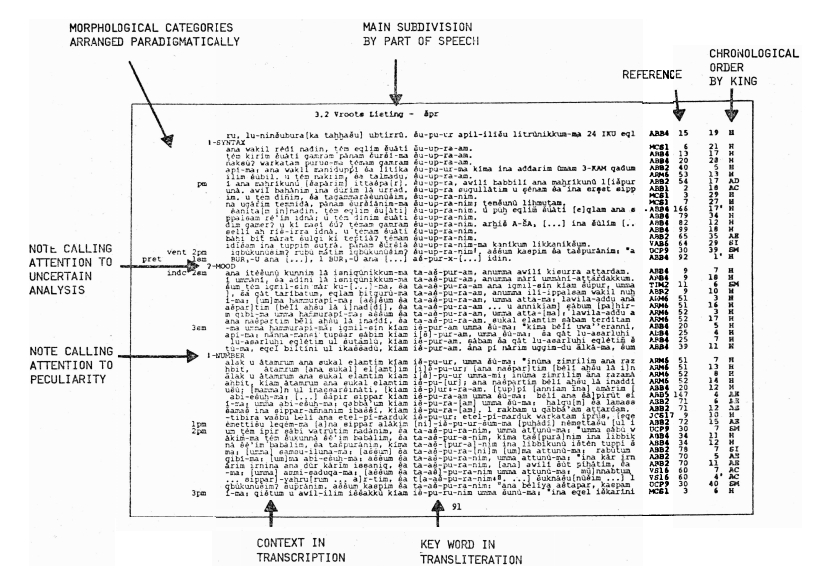
(3) Morphemic and syntactic analysis
Back to top: Project's history: the Texts domain
Programming
All programming was done by John L. Settles.
Back to top: Project's history: the Texts domain
1977-2012: Ebla
The experience gained in these early experiments served us in good stead in approaching the digitalization of the texts of Ebla. As a member of the Committee for their publication, I was entrusted with that task in 1977, and I set to work on it by organizing the data entry of the data (still with a keypunch machine), according to the coding strategy developed for the Old Babylonian corpus. It was slow work, which led to a number of results.
In 1982, I published a long article on Ebla graphemics that carried forward the study done on Old Babylonian and Western Akkadian.
In 1988, James H. Platt published “Notes on Ebla Graphemics” in Vicino Oriente 7, pp. 245-48.
In 1990, I published another article on the Ebla Electronic corpus, which gave the details of what a digital edition entailed. In the same volume, James H. Platt and Joseph M. Pagan published an article on “Orthography and Onomastics Computer Applications in Ebla Language Studies.”
In 1992 I published “The Ebla Electronic Corpus: Onomastic Analysis,” where, going beyond graphemics, I showed the way in which a digital approach can help in the study of personal names.
Platt and Pagan were two of three graduate students who worked on the project. They all went on to produce the following UCLA PhD dissertations:
- 1993 – James H. Platt, Eblaite Scribal Tendencies: Graphemics and Orthography;
- 1994 – Joseph M. Pagan, Morphological and Lexical Study of Personal Names in the Ebla Texts, published in 1998 as volume 3 in the Archivi Reali di Ebla. Studi;
- 2005 – Terrence L. Szink, Computer-Aided Analysis of the Semitic of the Ebla Tablets.
As the digital edition of the Ebla texts took a new direction under the leadership of Lucio Milano, I had an opportunity in 2011 to write a brief overview of the work done previously in the CD publication of the texts: “Digital Edition and Graphemic Analysis of the Ebla Texts“.
In 2012, I started a website entitled Linguistic Analysis of Akkadian which had as its goal to assemble online the data on which we had been working. The site remained unfinished, but three corpora are available, if still in a beta version.
- The Terqa tablets
- The electronic version of the data contained in the disk attached to the J.M. Pagan’s volume A Morphological and Lexical Study of Personal Names in the Ebla Texts (ARES 3, Roma 1998).
- A portion of hte EBla texts – Also in 2012, Massimo Maiocchi placed online
Back to top: Project's history: the Texts domain
Back to top: Project's history: the Texts domain
1979-1984: Cybernetica Mesopotamica and collaboration with Saporetti
The dissemination of the results remained an open issue, and in 1979 I started two series of volumes published by Undena Publications: Data Sets and Graphemic Categorization. They were both subsumed under the title of Cybernetica Mesopotamica which appeared then for the first time in print.
Three volumes were published in the Data Sets series, and one in the Graphemic Categorization series, and they were all dedicated to Middle Assyrian material, resulting from the collaboration with Claudio Saporetti and his project ALTAN - “Analisi Linguisitica dei Testi Assiri e Nuziani.”
It was clear from the beginning that paper publication of this material was inadequate, but it was the only way in which the results of the project could at that point be made known. The introduction to GC 2 made a good case for the notion of “graphemic categorization” as a method for the in depth analysis of cuneiform texts from this point of view – a type of analysis that could only be possible with the digital structuring of the text. (Note: the volume GC 1, mentioned in this text was never published: it was intended as a fuller introduction to graphemic analysis.)
Back to top: Project's history: the Texts domain
1987-98: Distribution disks
The first attempt to compensate for the inadequacy of the paper medium was the use of floppy disks.
In 1987 we published, within Undena Publications, the Terqa Texts Data Base.
In 1989, we published in the same format Saporetti’s digital version of the Middle Assyrian Laws, previously published (1984) in paper version.
In 1998, Pagan’s volume (ARES 3) also contained a floppy disk with the data in electronic format.
Both carried the Cybernetica Mesopotamica imprint.
Needless to say, floppy disks, too, went rapidly into disuse, and no more were produced. But the effort is significant in that it pointed to the importance of making available an electronic version suitable for a proper digital exploitation of the data.
Cf. also the Undena’s Bibliotheca Mesopotamica Dual Editions series (editor: F. Buccellati.)
Back to top: Project's history: the Texts domain
Back to top: Project's history: the Texts domain
2012-14: Old Babylonian Royal Letters
Going back to the early OBLAP project, John L. Hayes, with the assistance of Terri-Lynn Tanaka, resumed work on a select group of Old Babylonian letters, those from the royal chancery of Babylon. For these, a full morphemic and a partial syntactic analysis had been carried out, and the material was now revised and prepared for uploading to the server.
Back to top: Project's history: the Texts domain